Top websites block Google from training AI models on their data. Nowhere near as much as OpenAI, though.

Google launched a new tool that lets publishers opt out of training Google's AI models.
More and more top-ranking websites are using it.
Google is not being blocked as much as OpenAI, though. There may be a good reason for this.
There's a grand bargain at the heart of the web: A small piece of code that has maintained order for decades.
Robots.txt lets website owners choose whether to let Google and other tech giants scrape their online content. Most sites have let Google do this because the company distributes so much valuable traffic.
Then, the AI wars began. It turns out that all this content has been stored in datasets that are the foundation for training powerful AI models, including those from OpenAI, Google, Meta, and others. These models often answer user questions directly, so less traffic may be distributed and the grand web bargain begins to unravel.
Part of Google's response has been to launch a new tool that lets websites block the company from using their content for training AI models. It's called Google-Extended. It came out in September, and it's getting some pickup.
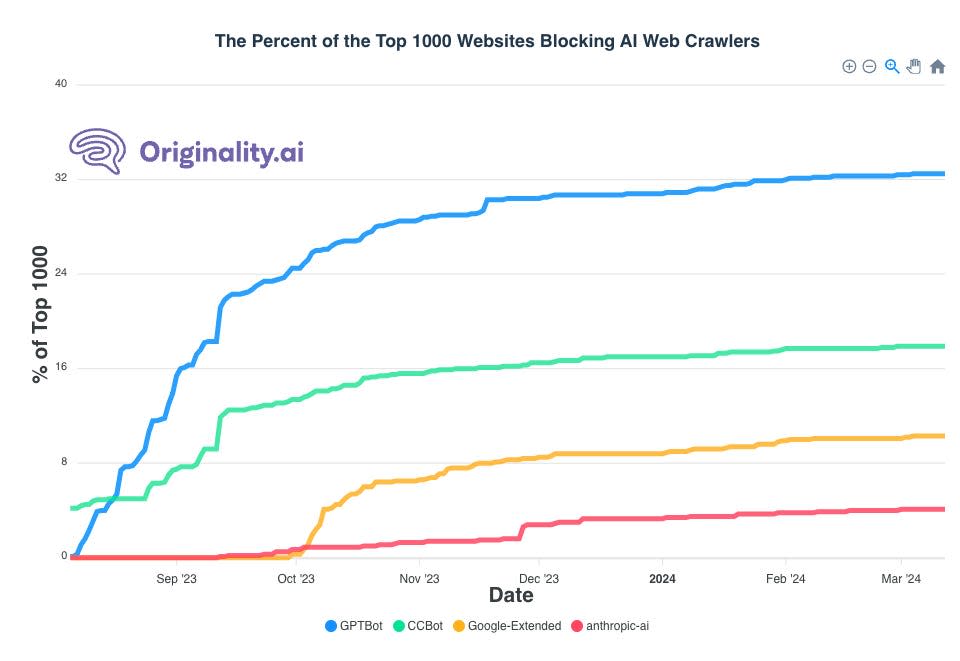
Data shared by Originality.ai shows the Google-Extended snippet is being used by about 10% of the top 1,000 websites, as of late March.
The New York Times has enabled the Google-Extended blocker, according to a review of its robots.txt file. The publication, which is in a heated AI copyright battle with OpenAI, has also blocked that startup's access to its content.
It's on a warpath with other companies that either tap online data for AI model training, or compile this type of data for others to use in similar ways.
"Use of any device, tool, or process designed to data mine or scrape the content using automated means is prohibited without prior written permission," NYT states on its robots.txt page.
Prohibited uses include "the development of any software, machine learning, artificial intelligence (AI), and/or large language models (LLMs)," the publisher adds. A spokesperson for NYT declined to comment.
Google blocked less than OpenAI
For Google-Extended, other websites have switched this on too, including CNN, BBC, Yelp, and Business Insider, the publisher of this story.
However, Google-Extended has had much less pickup than OpenAI's GPTBot, which is hovering at around 32% of the top 1,000 websites. CCBot, offered by Common Crawl, also has been switched on more.
BI asked Originality.ai CEO Jonathan Gillham why Google-Extended is being used less than other AI training data-blockers.
He said there's a risk that if websites block Google's access to training data, their content won't be included in future outputs from the company's AI models.
"If a query is 'What is the best deep dish pizza in Chicago?' and a Pizza shop excludes Google's AI from using its website data to train on, then it will not have any knowledge of that restaurant and be unable to include it in its response," Gillham explained.
Google stressed that using Google-Extended does not impact how websites show up in Search results. That includes the company's new genAI-powered version of Search, called Search Generative Experience, or SGE, which is in an early testing phase.
It's unclear if Google will launch SGE fully in the future, or how much different it will be from the traditional Google search engine.
Those decisions will go a long way to deciding the future of the web in this new AI world.
Axel Springer, Business Insider's parent company, has a global deal to allow OpenAI to train its models on its media brands' reporting.
Read the original article on Business Insider
